

Docker Compose est un outil très pratique de Docker qui offre la possibilité d’orchestrer un ensemble de container sur une seule et même machine (à l’inverse de Docker Swarm, qui lui orchestre ses containers sur plusieurs serveurs).
Je choisis ici de déployer un stack ELK (Elastic Search, Logstash, Kibana) qui va me permettre d’obtenir une solution d’analyse de log performante et complète !
Stack ELK késako ?
Pour info, on dit maintenant the Elastic Stack 😛
ElasticSearch
ElasticSearch est un serveur basé sur Apache Lucene avec un moteur de recherche, d’indexation et une analyse en temps réel des données. Il fonctionne avec une architecture REST (REpresentational State Transfert).
Logstash
Logstash est un outil de collecte, d’analyse et de stockage des logs. C’est un pipeline open source qui ingurgite et traite simultanément plusieurs données et ceux provenant d’une multitude de sources à la fois. Il exporte ces données vers Elastic Search.
Kibana
C’est l’interface web d’ElasticSearch permettant de rechercher des informations stockées par Logstash dans ce-même ElasticSearch. Kibana permet via son interface de créer des diagrammes , nuages de points, camemberts et autres schéma représentatif du flux de données souhaités.
Docker Compose
Installation
Docker Compose n’est pas installé par défaut avec le daemon Docker.
Téléchargement de la dernière version de Docker Compose
sudo curl -L https://github.com/docker/compose/releases/download/1.17.0/docker-compose-`uname -s`-`uname -m` -o /usr/local/bin/docker-compose
On rend le binaire exécutable
sudo chmod +x /usr/local/bin/docker-compose
On vérifie l’installation
$ docker-compose version docker-compose version 1.16.1, build 6d1ac21 docker-py version: 2.5.1 CPython version: 2.7.13 OpenSSL version: OpenSSL 1.0.1t 3 May 2016
Tout est ok ! 😉
Création d’un alias
Car écrire tout le temps docker-compose c’est un peu long à force..
nano ~/.bash_aliases
Et on y ajoute
alias compose='docker-compose'
Pour que l’alias soit maintenant prit en compte
source ~/.bash_aliases
Vérification
$ compose version docker-compose version 1.16.1, build 6d1ac21 docker-py version: 2.5.1 CPython version: 2.7.13 OpenSSL version: OpenSSL 1.0.1t 3 May 2016
Si jamais on souhaite supprimé l’alias crée
unalias compose
GitHub
Récupération du dépôt
git clone https://github.com/deviantony/docker-elk
Analyse du docker-compose.yml
Toujours effectué une analyse du fichier docker-compose.yml !
Version
version: '2'
La version 2 du fichier compose est compatible avec Docker 1.10 et plus.
Actuellement,le fichier compose est rendu à la version 3 (3.4), et embarque plus de fonctionnalités (cache, label, deploy..) que la version 2 . Compose file version 3 reference
Build
elasticsearch: build: elasticsearch/
Contrairement à l’instruction image, l’instruction build signifie que Docker utilisera d’abord une image basée sur un Dockerfile en local (donc dans le répertoire indiqué : elasticsearch/) contenant le Dockerfile en question, qui indique lui-même de récupérer une image bien précise : FROM docker.elastic.co/elasticsearch/elasticsearch:5.6.3.
Volumes
volumes: - ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml
L’instruction volumes permet de mapper un répertoire/fichier entre notre hôte Docker et notre container. Le fichier elasticsearch.yml présent sur notre hôte sera monté et présent dans le container avec le chemin /usr/share/elasticsearch/config/elasticsearch.yml. Donc pour les modifs à faire avant de démarrer le cluster, c’est sur notre fichier hôte ! Je modifie pour ma part le nom du cluster qui s’affichera (cluster.name). C’est un équivalent de $ docker container run -v HOST_PATH/CONTAINER_PATH .. pour du Docker en CLI.
Ports
ports: - "9200:9200" - "9300:9300"
Mappage de ports entre l’hôte Docker et notre container, toujours sous le format hôte:container. C’est un équivalent de $ docker container run -d -p 8080:80 nginx pour le lancement d’un container nginx accessible sur le port 8080 de l’hôte en background avec la CLI Docker.
Environment
environment: ES_JAVA_OPTS: "-Xmx256m -Xms256m"
L’instruction environnement permet de spécifier des variables lors du lancement du container. Sans rien toucher, la JVM fera 256Mo. Une fois le container lancé, on retrouve cette variable avec un cat config/jvm.options.
Networks
networks: - elk
L’instruction networks spécifie d’utiliser le network elk, définie à la fin du fichier docker-compose.yml. Cette instruction est semblable à du Docker CLI avec $ docker network create – -driver bridge elk
networks: elk: driver: bridge
Un network est crée, s’appellant elk. Ce network est basé sur le driver bridge. Par défaut, lors de l’installation de Docker, trois networks sont crées :
•bridge, basé sur le driver bridge qui permet la communication des containers sur un même hôte. Ce network correspond à l’interface docker0 lors d’un ifconfig.
•host, basé sur le driver host qui permet de ce stacké directement sur le réseau de la machine hôte.
•none, basé sur aucun driver, qui ne permet pas de connexion sur l’extérieur et qui possède une seule interface qui est localhost.

Networks de base crée lors de l’installation de Docker

Un nouveau network crée après le lancement de mon stack ELK basé sur le driver bridge
Depends
depends_on: - elasticsearch
Dans un Docker compose, depends_on permet de lancer les services dans l’ordre de dépendance. Dans notre cas, Logstash et Kibana démarrons après que Elasticsearch soit lancés. Par contre, depends_on n’attend pas que le service Elasticsearch soit prêt, il attend simplement son démarrage. Pour qu’il puisse attendre qu’un service soit disponible avant de démarrer, on peut utiliser un outil de contrôle de démarrage.
Lancement du stack
Vérification
Avant de démarrer mon stack, je rajoute dans mon docker-compose.yml un argument container_name pour spécifier un nom personnalisé à mes containers.
Pour vérifier si le docker-compose.yml est correct, la commande docker-compose config verifie et liste ou non les erreurs du fichier. Si pas de message en rouge, c’est O.K 😉 (attention à l’indentation du fichier).
Démarrage
Lancement du stack en background avec l’argument -d
compose up -d
Vérification du bon lancement des containers du stack
$ compose ps elasticsearch_supras /bin/bash bin/es-docker Up 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp kibana_supras /bin/sh -c /usr/local/bin/ ... Up 0.0.0.0:5601->5601/tcp logstash_supras /usr/local/bin/docker-entr ... Up 0.0.0.0:5000->5000/tcp, 5044/tcp, 9600/tcp
Pour afficher seulement l’ID des containers
$ compose ps -q 918241520dd40d1b3dc2aa214fae1d63e01353c7d3e0034a9a0174c9684f5865 5bdba9ac940e9e61ee2a230160ebba01986ad0ba6eeda47898108dbe7cd07d56 9994b5a6ccd23c521078272fd22a576f05c6aed77110fe46a9d91a95a41f6554
Interface web
La connexion se fait sur l’interface Web de Kibana, sur le port 5601. Kibana met quelques minutes à se lancer, mais une fois que c’est bon …

Interface web Kibana
Index Pattern
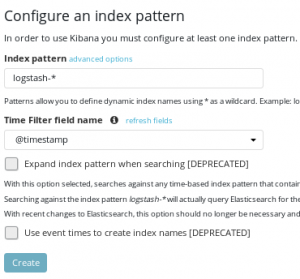
Définir un pattern permet d’exécuter une analyse, une recherche, créer des graphiques et exporter/importer des données. Il est nécessaire d’initier une première connexion vers Logstash pour pouvoir configurer Kibana avec comme pattern logstash-*.
Netcat va me permettre d’initier une première connexion de mon hôte Docker sur le port TCP 5000 et envoyer des données factices à Logstash pour qu’il puisse les traiter
$ nc localhost 5000 < /mon_fichier/factice_log.txt
On peut maintenant créer un patern logstash avec comme filtre @timestamp qui correspond à l’heure du traitement des données. On peut choisir ou non d’activer ce filtre.
Filebeat
Filebeat permet de centraliser tout les fichiers logs, évènements et autres journaux pour ensuite alimenter Logstash. C’est un produit open source de la société Elastic, qui s’accorde donc parfaitement avec the Elastic Stack.
Pour l’installation, rien de compliqué (récupération du paquetage .deb et installation)
curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.0-amd64.deb sudo dpkg -i filebeat-6.0.0-amd64.deb
Le fichier de configuration se situe dans /etc/filebeat/filebeat.yml
De base il n’y a pas besoin de modifier énormement le fichier. Simplement faire attention aux logs que l’on souhaite envoyer (de base : /var/log/*.log) et à l’output choisis (il ne peut y en avoir que un entre elasticsearch et logstash). Cela demande un peu plus de configuration du TLS.
Deux commandes nous permettent de vérifier la bonne configuration de filebeat
$ filebeat test config $ filebeat test output
Filebeat propose différents modules. On retrouve ces modules dans /etc/filebeat/modules.d/
Le module Nginx par exemple va permettre de récolter les logs d’accès et d’erreurs du serveur web.
Le module system quand à lui permet récolter les différents logs systèmes présent de base (/var/log/) sur toutes distributions basées sur Linux/Unix.
Filtres de recherche
Une fois nos logs traités, Kibana met à disposition plusieurs filtres de recherches pour investiguer dans nos logs.
![]()
Filtres avec chaîne de caractères
Requêtes HTTP émises avec le navigateur Mozilla
"Mozilla/5.0"
Requêtes contenant le message : « Merci de vous authentifier sur notre site »
"Merci de vous authentifier sur notre site"
Filtres avec champs spécifiques
Protocole HTTP
type: http
Requêtes émises par un hôte précis
host: 192.168.1.10
Requêtes émises par un port précis
port: 52771
Rechercher un code d’erreur HTTP
status:[400 TO 499]
Ce ne sont que quelques exemples basiques.. pour aller plus loin, c’est ici !
Arrêt du stack
Mettre en pause notre stack
$ compose pause
Sortie du mode pause
$ compose unpause
Arrêt du stack
$ compose stop
Arrêt du stack et suppression des containers, images, volumes et networks
$ compose down